featured article
Beware the Geek Squad Scam Email: Tips to Stay Safe Online
Latest articles


Venmo is a popular cash transfer app used in the United States. It allows users to send and receive payments easily. However, there are potential scams and frauds associated with Venmo. It is important to stay alert and protect yourself from these scams to ensure the safety of your transactions. Key Takeaways Be cautious of …
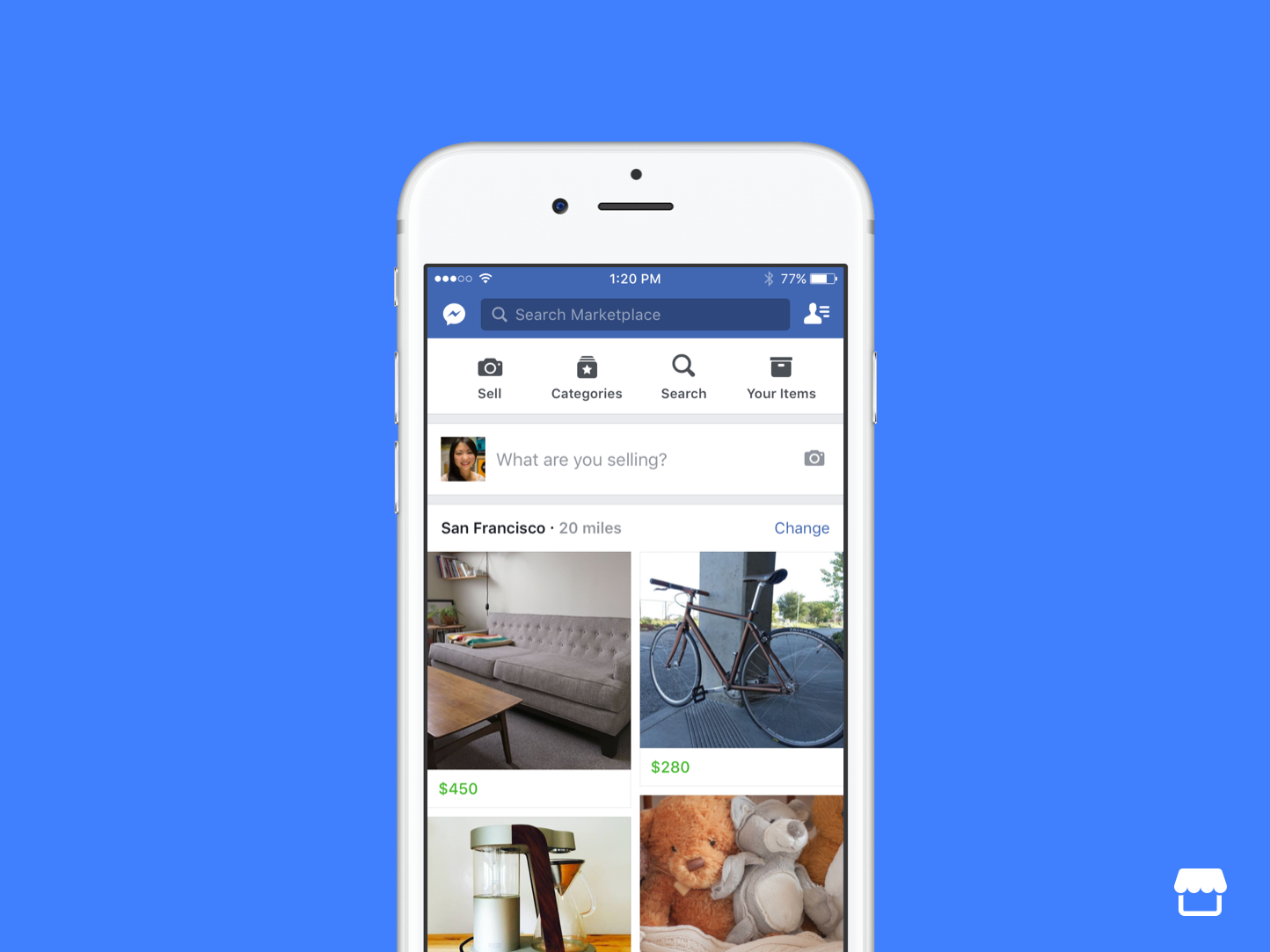
Facebook Marketplace has become a popular platform for buying and selling goods online. However, it is not without its risks. Scammers are known to exploit unsuspecting users, making it crucial to stay vigilant and protect yourself from potential scams. In this article, we will provide you with essential tips and tricks to help you avoid …

Are you concerned about the security of your PayPal account? With the rise in online scams and phishing attempts, it’s important to stay informed and take proactive measures to protect yourself. In this guide, we will provide you with essential information on how to safeguard your PayPal account from fraudulent emails and scams. Key Takeaways: …

Are you concerned about the allegations of a Geek Squad scam? Worried about falling victim to Geek Squad fraud or a tech support scam? In this comprehensive guide, we delve into the truth behind the accusations and provide you with valuable information to help you make informed decisions when it comes to Geek Squad services. …

PeopleLooker is a data broker that collects and posts personal information on their searchable database. This information can be accessed by anyone, putting your privacy and safety at risk. To protect yourself, it is important to opt out of PeopleLooker and remove your information from their databases. Follow the step-by-step guide below to opt out …

Are you concerned about your phone number privacy? Worried about your personal information being sold to people search sites? Opting out of these directories can help protect your data. In this article, we will guide you through the steps to opt out of Numlookup, one of the most popular phone number search sites. By following …

Data search sites like Whitepages.com make it easy to find personal information, but this exposes you to privacy risks. Removing your name and information from Whitepages is crucial in protecting your identity and ensuring your privacy. This article provides easy steps to opt out of Whitepages and remove yourself from its listings. Key Takeaways: Opting …

Opting out of data brokers is an important step in protecting your privacy, and 411 Locate is no exception. In this guide, we will walk you through the process of opting out of 411 Locate, providing you with easy steps to remove your information from their website. We will also discuss the importance of opting …

Are you concerned about your online privacy and want to remove your personal information from CheckPeople.com? CheckPeople is a background check website that collects data from public records and provides comprehensive reports on individuals. To protect your data and maintain your privacy, it is recommended to opt out of CheckPeople. In this guide, we will …

Are you tired of receiving unwanted calls from Dynata? These calls can be a nuisance and a potential threat to your privacy. Scammers often disguise themselves as Dynata to steal personal information, so it’s important to take action and protect yourself. In this article, we will explore effective ways to stop Dynata calls and regain …

Steam card scams have become a widespread issue in the digital age, posing a serious threat to unsuspecting victims. It is essential to educate yourself about these scams and take the necessary precautions to safeguard your hard-earned money. In this article, we will delve into the specifics of steam card scams, how they work, and …

ZabaSearch is a people search and reverse phone lookup website that provides detailed personal information about individuals. It collects data from publicly available sources, such as court records, property transactions, and voter registration records. While ZabaSearch doesn’t maintain a personal information database, it allows users to search for and access this information. Opting out of …

Are you concerned about your personal information being displayed on Arrests.org? In this article, we will guide you through the process of utilizing the Arrests.Org Opt Out feature to remove your information from the website. By following the steps outlined below, you can take control of your digital presence and protect your privacy. Key Takeaways: …

Are you concerned about your privacy and want to remove your phone book listing from USPhonebook? We’ve got you covered. Follow these easy steps to opt out of USPhonebook and reclaim your privacy. It’s a simple process that will only take a few minutes of your time. Key Takeaways: Opting out of USPhonebook helps protect …

If you are searching for a solution to remove your personal information from TruePeopleSearch, it is likely that your data is on the site. TruePeopleSearch is a public people search site that aggregates personal information and may have your name, age, addresses, phone numbers, email addresses, and even information about your relatives listed publicly. To …

FastPeopleSearch is a popular data aggregator that allows anyone to access your personal details, including phone numbers, email addresses, home addresses, and even court records. To protect your online privacy, follow this comprehensive guide to effectively remove your information from FastPeopleSearch. Key Takeaways: Removing yourself from FastPeopleSearch is crucial for privacy protection Opting out of …

Are you tired of receiving unwanted calls from Dynata? These calls can be a nuisance and a potential threat to your privacy. Scammers often disguise themselves as Dynata to steal personal information, so it’s important to take action and protect yourself. In this article, we will explore effective ways to stop Dynata calls and regain …

Welcome to our comprehensive guide on how to opt out of USPhoneBook and remove your personal information from their database. USPhoneBook is a data broker site that provides a reverse phone lookup service, but it also includes personal information such as names, addresses, and phone numbers. Taking control of your privacy is essential, and we …

Are you looking for love online? It’s important to be aware of the risks and protect yourself from online dating scams. With more than 40 million Americans using online dating services, it’s crucial to take safety precautions when connecting with potential partners. Key Takeaways: Use different photos for your dating profile and avoid connecting with …